After getting the MacGPT app, which is essentially toolbar access to GPT, and after user requests, I realised this can’t be that hard to implement in Liquid, so here is the plan: Use Liquid as an interface to take whatever the user comes across or writes and in a few clicks send to an AI system (GPT) with a custom prompt, to help both students, teachers and general knowledge workers:
Interaction
A new top level command in Liquid called ‘Ask’, with shortcut (A) to send selected text to ChatGPT, with an associated prompt:

The sub menu contains options to choose a prompt/how to preface the selected text (not all are on/visible by default):
- ‘What is’ (W)
- ‘Write in academic language’ (A)
- ‘Show me more examples’ (S)
- ‘What relates to’ (R)
- ‘Show me counter examples to’ (C)
- ‘Is this correct?’ (I)
- ‘Check for plagiarism’ (P)
- ‘Explain the concept of (E)’
- ‘Create a timeline of’ (T)
- ‘Discuss the causes and effects of’
- Create a quiz with 5 multiple choice questions that assess students’ understanding of
- ‘Edit’ (which opens Liquid’s Preferences to allow the user to design their own)
Results
Since the API can be slow, as can be seen when using MacGPT and other interfaces, there will be a flashing cursor while waiting for the results. If it is easier to produce the results in a web view, then we will do that.
Note, as in the error for 1980, AI is not at the stage where it can be trusted to always be correct, and maybe this will never happen. Nevertheless, it is a tool and user’s need to learn how to use it, including checking what it produces:

Development note: This should ideally be presented in a non-full screen, floating window, for the user to dismiss when done or leave open.
Preferences/Key (how it works)
Here the user will be able to customise and make their own preface text/prompts. Enter a name, shortcut and full text of prompt/preface text to send to Chat PGT:
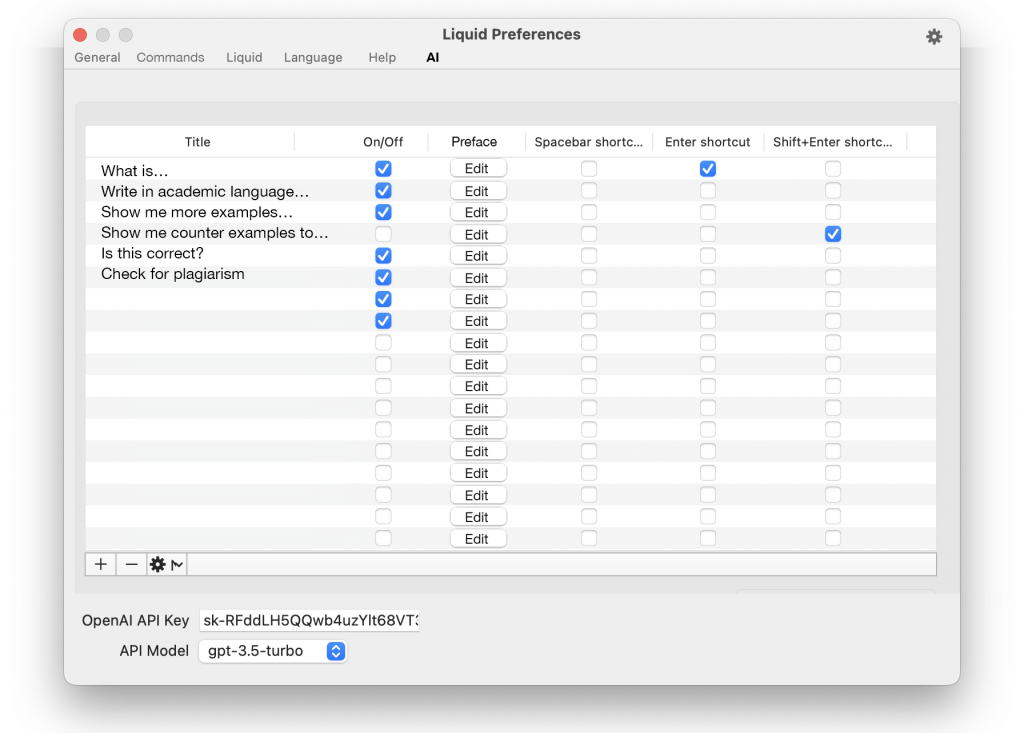
Preferences is also where user’s add their own API Keys for GPT, as inspired by how MacGPT does it, and also option to choose model.
On first try of an AI service, Liquid will show a dialog asking for the API key. If dismissed, it will simply ask for it again on next attempt.
Future updates should be able to let the user choose other AI models, including Google Bard.
Notes on longer prompts
Some of the actual prompts will be longer than indicated above. This will need some basic experimenting. For example:
Check for plagiarism: I want you to act as a plagiarism checker. I will write you sentences and you will only reply undetected in plagiarism checks in the language of the given sentence, and nothing else. Do not write explanations on replies. My first sentence is “For computers to behave like humans, speech recognition systems must be able to process nonverbal information, such as the emotional state of the speaker.”